The Model Context Protocol: A Strategic Analysis and Technical Blueprint for Memory-Augmented LLMs
The analysis of modern large language model (LLM) architectures and their operational constraints reveals a pivotal architectural shift. Traditional, stateless LLMs, despite their immense size and intelligence, are fundamentally limited by their inability to retain and reference information beyond a single, ephemeral session. This limitation has historically been addressed with ad-hoc, first-generation solutions like Retrieval-Augmented Generation (RAG), which, while effective for simple tasks, are brittle and insufficient for complex, stateful applications. The Model Context Protocol (MCP) emerges as a strategic response to these limitations, offering a standardized, scalable, and secure framework for augmenting LLMs with persistent, external memory.
The central thesis of this report is that the question is not a simple choice between "MCP or no MCP," but rather a qualified endorsement. For applications that require a sophisticated understanding of an evolving context, multi-turn dialogue, long-term user preferences, or multi-step agentic workflows, the adoption of a standardized protocol like MCP is an architectural imperative. Such a protocol provides the necessary foundation for building production-grade, reliable, and secure AI systems that can operate seamlessly over time. For simpler, transient tasks, such as retrieving a single document or a few examples, a lightweight, ad-hoc RAG implementation may remain a sufficient and cost-effective solution. In essence, MCP serves as a blueprint for the next generation of AI systems, enabling them to transition from stateless predictors to adaptable, interactive, and continuously learning assistants.
The key findings indicate that MCP provides a secure and interoperable means to extend LLM capabilities without the need for expensive and resource-intensive model retraining. However, its implementation requires a non-trivial investment in a distributed client-server infrastructure and an understanding of its security-by-design principles.
The Foundational Paradigm Shift: Moving Beyond Stateless LLMs
The "Memory Wall" in the Age of AI: A Dual Bottleneck
The evolution of computing has long been dominated by the processor-centric paradigm, where the central processing unit (CPU), or its specialized counterparts like GPUs, acts as the singular hub for all computation. Data must be moved from various storage and memory devices to the processor before it can be processed.1 This constant data movement creates a significant bottleneck, known as the "memory wall," which constrains both performance and energy efficiency. Research has shown that even the most powerful processors can spend more than 60% of their time waiting for data to be transferred between memory and the processor.1
This foundational hardware limitation has been profoundly exacerbated by the rise of large language models. While early LLMs were primarily focused on increasing model size, recent architectural innovations like Mixture of Experts (MoE) are causing compute requirements to trend downward. Concurrently, the demands for higher memory capacity and longer context lengths are growing exponentially.3 This combination of factors has effectively shifted the primary bottleneck from computational power to memory capacity and bandwidth. The hardware and low-level software advancements required to address this physical limitation are directly connected to the development of high-level software paradigms. For instance, techniques like PagedAttention, which manage the LLM's key-value (KV) cache by breaking it into small, on-demand blocks similar to virtual memory, are essential for reducing memory fragmentation and enabling the kind of high-throughput, variable-length requests that a protocol like MCP would generate.4 Without these underlying hardware and low-level software optimizations, the promise of dynamic, scalable context enabled by a high-level protocol would be economically and operationally unfeasible.
An LLM operating solely with its internal parameters and a limited, ephemeral context window is akin to a human with severe anterograde amnesia—it possesses immense knowledge but is unable to learn from or apply recent experiences. This is why LLMs are often described as stateless and "frozen in time," treating each new query as a standalone task.5
The Limitations of First-Generation Memory: Why RAG Isn't Enough
To overcome the inherent statelessness of LLMs, developers have widely adopted first-generation memory solutions, most notably Retrieval-Augmented Generation (RAG). RAG works by using external databases, typically vector stores, to retrieve relevant information that is then injected into the LLM's context window as part of the prompt. This approach is straightforward and often "good enough" for basic use cases like documentation retrieval or simple question-answering.
However, the research identifies a series of fundamental flaws in RAG that prevent it from serving as a true, robust memory system. RAG is criticized as being a "search tool with the label 'memory' applied to it," creating false expectations about its capabilities.5 The primary shortcomings include:
Context Fragmentation: RAG retrieves semantically similar but often disconnected chunks of information. The LLM is then forced to "stitch these pieces together," which can lead to incomplete or inaccurate results and, in many cases, hallucinations.
Poor Associative Reasoning: The mechanism of vector search struggles with complex, multi-hop queries that require a deeper level of reasoning, such as analyzing trends or causality. It can also fail at associative tasks. For example, a query about a user's anniversary might retrieve generic holiday information instead of specific memories tied to that user's relationship history.
Relevance Drift: In large datasets, the most relevant information can be buried under noisy, irrelevant matches, making effective retrieval challenging.
The recognition of these limitations has spurred a search for more sophisticated, biologically inspired architectures. Research points to a growing consensus that effective LLM memory should mimic the nuanced, selective, and associative nature of human cognition.6 Concepts such as "selective forgetting," where older, less important memories decay gracefully while core concepts are retained, are proposed as superior alternatives to the binary "present or purged" approach of traditional vector databases.6 The development of a structured protocol for context management, as seen in MCP, is an attempt to impose a higher-level organizational logic on unstructured data, thereby addressing the core deficiencies of RAG.
The Model Context Protocol (MCP) Defined
Core Concepts and Architecture
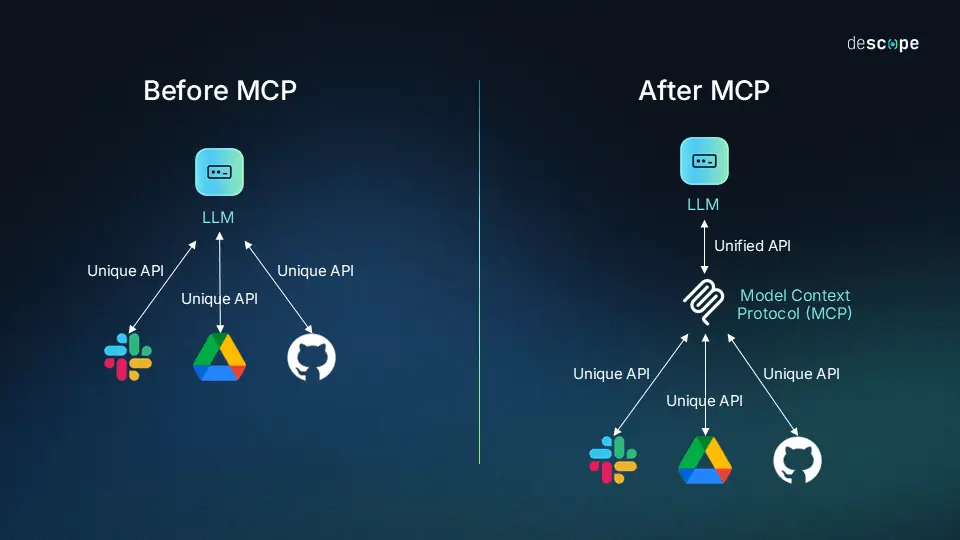
The Model Context Protocol (MCP) is an open, standardized protocol that dictates how applications provide context to large language models.10 A widely used analogy likens MCP to a "USB-C port for AI applications".10 Just as a USB-C port enables a standardized connection between a computer and a wide variety of peripherals, MCP provides a unified way to connect AI models to external data sources and tools, fostering interoperability and a growing open-source ecosystem.10
The protocol is built on a modular client-server architecture. The main participants are:
Hosts: The AI application, such as Claude.ai or a Visual Studio Code extension, that initiates and manages the user experience.
Clients: A component instantiated by the host for each connection to a specific server. The client maintains this one-to-one connection and facilitates communication.
Servers: Independent programs that provide specific context and capabilities to the clients. These can be run locally or remotely and are designed for a focused purpose, such as a file system server or a travel planning server.
The underlying communication layer of MCP utilizes JSON-RPC 2.0 messages, which allows for stateful connections and enables clients and servers to negotiate capabilities at the start of a session. This structured foundation provides a robust and reliable channel for data exchange.10
The Three Pillars of Contextualization
The full power of the MCP is realized through its three core building blocks, which collectively provide a comprehensive framework for managing and exposing external context to an LLM:
Resources: These are application-controlled data sources that provide the LLM with dynamic, queryable knowledge.10 Resources are analogous to
GET endpoints in a REST API, providing data from sources like files, databases, or public APIs without performing significant computation.10 They are identified using URIs and can be either fixed (direct resources) or parameterized (resource templates) for dynamic access to data.10
Tools: Tools are model-controlled functions that empower the LLM to perform specific actions in the real world.10 These functions are defined by a JSON Schema, which allows the LLM to understand their purpose, inputs, and outputs.10 Examples of tools include searching flights, sending an email, or creating a calendar event. Due to their ability to execute arbitrary code, tools are subject to strict security protocols. Tool execution requires explicit user consent, and hosts are required to obtain this approval from the user before invoking any tool.10 This human-in-the-loop design is a fundamental aspect of the protocol, ensuring transparency and security.
Prompts: Prompts are user-controlled, pre-defined templates for common tasks.10 Unlike tools, which are invoked by the model, prompts are explicitly triggered by the user to execute a specific workflow. They can be context-aware, referencing available tools and resources to create comprehensive, reusable workflows.10
The security-by-design principles of the protocol are a critical component of its architecture. Because MCP enables LLMs to access sensitive user data and execute code paths, the protocol places a heavy emphasis on user consent and control. The security features are not just a post-hoc addition; they are an integral part of the protocol's design. This is evident in the requirement for explicit user approval for every tool call and even for "sampling" requests, where a server requests a language model completion from the client.10 This mechanism ensures that the user maintains oversight over all data access and actions, a necessary requirement for building trustworthy agentic AI systems.
A Comprehensive Analysis: The Pros and Cons of MCP Adoption
The Advantages: Unlocking Next-Generation AI Capabilities
The adoption of MCP provides a host of benefits that directly address the core limitations of stateless LLMs and first-generation memory solutions:
Enabling True Statefulness: By providing a structured, persistent, and cross-session memory, MCP allows LLMs to remember facts, user preferences, and previous actions.6 This solves the problem of users being forced to repeat information and allows applications to adapt to a continuous, evolving context, leading to a much-improved user experience.6
Enhancing Factual Consistency and Mitigating Hallucinations: When LLMs are grounded in stored facts from a retrieval system, their propensity to hallucinate—fabricating information to fill gaps in their knowledge—is significantly reduced.8 MCP's use of Resources, which provide dynamic and up-to-date knowledge, helps anchor the LLM's responses in structured, verifiable data, thereby improving factual accuracy.8
Operational and Cost Efficiency: MCP's selective context management allows for a more intelligent use of the LLM's fixed context window. Instead of passing an entire, redundant conversation history with every query, MCP enables "smart write" strategies, which summarize and store only the most critical information, and "smart read" strategies, which retrieve specific, relevant data on demand.6 This approach dramatically reduces token usage, lowers computational costs, and improves response latency.6
Interoperability and Ecosystem Growth: As an open standard, MCP allows a single server to be built for a specific data source or tool (e.g., a Google Drive server) and then consumed by any number of compatible clients (e.g., Claude, a custom enterprise application, a VS Code extension).10 This eliminates the need for developers to build custom, one-off connectors for every application and fosters an open-source ecosystem, which accelerates development and innovation.10
The Disadvantages: Navigating Technical and Operational Challenges
Despite its benefits, the adoption of a protocol like MCP is not without its challenges:
Implementation Complexity: Moving from a simple, monolithic LLM application to a distributed client-server architecture introduces significant upfront development and operational overhead. Organizations must invest in building, deploying, and maintaining a robust, scalable infrastructure that can handle the distribution of context and the orchestration of multiple servers.6
Limitations of Current Approaches: While MCP provides a powerful framework, its effectiveness is still tied to the maturity of the underlying memory systems. Advanced memory architectures like Graph RAG, while promising for enabling associative retrieval, introduce their own set of operational complexities, such as entity resolution, data invalidation, and the difficulty of defining a schema for a living, evolving knowledge graph.5
The Trade-off of Abstraction: The protocol's standardization provides immense value in interoperability and reusability. However, this same standardization could, in some cases, limit the flexibility required for highly specialized, custom applications that do not fit neatly into the framework of Tools, Resources, and Prompts. The decision to adopt a standardized system like MCP is a classic architectural trade-off between the benefits of a reusable, interoperable framework and the potential for a more highly optimized, bespoke solution. For most common use cases, the benefits of standardization and interoperability far outweigh the costs.
End-to-End Technical Blueprint: Deploying an MCP Server and Building Clients
Architectural Overview
The following blueprint provides a step-by-step guide for deploying a simple MCP server and integrating it with two distinct clients: a command-line interface using the Claude API and a Visual Studio Code extension. The system architecture involves a user interacting with a client, which in turn communicates with an MCP server hosted on Google Cloud Run. This server processes the request (e.g., retrieves a resource or executes a tool) and returns a structured response to the client. The client then incorporates this context into a prompt sent to a large language model, which generates the final output for the user.
Deployment: The MCP Server on Google Cloud Run
Prerequisites
To begin, the following must be in place on Google Cloud Platform:
A Google Cloud project with billing enabled.12
The Google Cloud SDK (
gcloud) installed and configured with the correct project.13The necessary APIs enabled: Artifact Registry, Cloud Build, and Cloud Run. This can be done with the
gcloud services enablecommand.13The user account must have the appropriate IAM roles, such as Project Creator and Billing Account User.12
Server Scaffolding
A minimal, containerizable web server can be built using Python and the Flask framework.
Create a working directory and navigate into it:
mkdir mcp-server && cd mcp-server
Create a main.py file with a simple web service that responds to HTTP requests:
main.py
from flask import Flask, request
app = Flask(__name__)
@app.get("/context")
def get_context():
"""A simple endpoint to act as a placeholder for a Resource."""
resource_id = request.args.get("resource_id")
if resource_id == "project-details":
return {
"id": "project-details",
"content": "The project is about deploying a memory-centric protocol server on Cloud Run."
}
return {"error": "Resource not found"}
if __name__ == "__main__":
app.run(host="localhost", port=8080, debug=True)
Create a requirements.txt file to define the dependencies:
requirements.txt
Flask==3.0.2
gunicorn==21.2.0
Create a
Procfileto instruct the production web server, Gunicorn, on how to run the application:
web: gunicorn --bind :$PORT --workers 1 --threads 8 --timeout 0 main:app
Deployment Walkthrough
Define a deployment region:
REGION="us-central1"
Deploy the application to Cloud Run. The --source flag instructs gcloud to build a container image from the local source code and automatically push it to Artifact Registry. The --allow-unauthenticated flag makes the service publicly accessible for demonstration purposes.
gcloud run deploy mcp-server \
--source. \
--platform managed \
--region $REGION \
--allow-unauthenticated
The command will prompt for repository creation and then deploy the service. The output will provide the service URL.
Table 1: Google Cloud Run Configuration Parameters
The following table summarizes key configuration parameters for a Cloud Run deployment, which are essential for making informed decisions about cost, performance, and scalability.
Parameter | Description |
| Permits unauthenticated requests, making the service publicly available.13 |
| Specifies the geographical location for the service deployment.13 |
| Instructs Cloud Build to containerize and deploy the application from the current directory.13 |
| Sets the maximum number of instances for the service, which is a key control for managing costs and scaling limits.15 |
| Defines the number of vCPUs allocated to each service instance (e.g., 1vCPU).12 |
| Defines the memory allocated to each service instance (e.g., 0.5GB).12 |
Integration: Consuming the MCP Server from Clients
Client 1: Integrating with Claude (API Call)
This approach uses the official Anthropic Python SDK to programmatically call a Claude model. The process involves first retrieving context from the deployed Cloud Run server and then structuring the prompt to include that context before making the final API call to Claude.
Install the SDK:
pip install anthropic
Set the API Key: Ensure the
ANTHROPIC_API_KEYenvironment variable is set with your key.16
Create the Python Script: The following script demonstrates the end-to-end flow.
import os
import requests
import anthropic
# Step 1: Define the endpoint for the deployed Cloud Run MCP server.
# Replace with your actual service URL.
MCP_SERVER_URL = "https://mcp-server-xxxxxx-uc.a.run.app"
def get_context_from_mcp(resource_id):
"""Calls the Cloud Run server to retrieve a specific resource."""
try:
response = requests.get(f"{MCP_SERVER_URL}/context?resource_id={resource_id}")
response.raise_for_status() # Raises an exception for bad status codes
return response.json().get("content", "No content found.")
except requests.exceptions.RequestException as e:
return f"Error retrieving context: {e}"
def main():
"""Main function to orchestrate the client-server interaction."""
client = anthropic.Anthropic()
# Step 2: Retrieve context from the MCP server.
project_context = get_context_from_mcp("project-details")
# Step 3: Structure the prompt with the retrieved context.
system_message = f"""You are a helpful assistant. Your knowledge is augmented by external context.
<context>
{project_context}
</context>
"""
user_query = "Summarize the key goal of the project based on the provided context."
# Step 4: Make the API call to Claude.
try:
message = client.messages.create(
model="claude-sonnet-3.5-20250514",
max_tokens=1000,
system=system_message,
messages=[{"role": "user", "content": user_query}]
)
print(message.content.text)
except Exception as e:
print(f"An error occurred with the Claude API call: {e}")
if __name__ == "__main__":
main()
Client 2: Integrating with Visual Studio Code (Extension)
For a deeper integration into a user's workflow, a custom VS Code extension can be created. This approach allows the MCP server to augment a developer's code editor, providing context-aware suggestions, refactoring, and code generation. The process involves using the official VS Code Extension API to scaffold a new project and handle the logic for calling the external MCP server.
Scaffolding: Use the Yeoman generator to create a new extension project in TypeScript.
npm install -g yo generator-code
yo code
Key APIs and Logic: The core logic of the extension resides in
extension.ts. The following steps are required:Register a Command: Use
vscode.commands.registerCommandto create a custom command (e.g.,extension.getProjectContext) that a user can trigger from the command palette or a keyboard shortcut.17Get User Context: Use
vscode.window.activeTextEditorto get the current file content or a user's text selection to pass as part of the request to the MCP server.17Call the MCP Server: Use
await fetch()to make an HTTPPOSTrequest to the Cloud Run server's URL. The request body would be a JSON object containing the user's selected context and the specific tool or resource to be invoked.17Render the Output: Once the response is received from the server, use VS Code APIs to render it to the user. This could be a simple notification (
vscode.window.showInformationMessage) or, for a more integrated experience, usingeditBuilder.insertto add the AI's generated content directly into the active editor at the cursor position.17
Table 2: Comparison of Client-Side Integration Methods
The following table compares the two primary methods for integrating with an MCP server, providing a quick reference for selecting the most appropriate approach for a given use case.
Client Type | Pros | Cons | Example Use Case |
API / SDK | Simple and fast to implement; minimal development overhead; works with any platform and language.17 | Cannot provide a rich, interactive user interface; limited to a command-line or programmatic experience.20 | Integrating context into an automated task, a backend service, or a simple chatbot.17 |
VS Code Extension | Deep integration with the editor and user workflow; can create a rich, interactive user experience.17 | Higher development overhead; requires specific knowledge of the VS Code API and a different development lifecycle.17 | Building a context-aware AI assistant for a specific domain (e.g., legal or medical research) that operates directly inside the developer's IDE.17 |
Conclusion and Strategic Recommendations
The "MCP or no MCP" question is a strategic one, representing a fundamental architectural choice for organizations building and deploying AI applications. The report's analysis indicates that the era of stateless, context-agnostic LLMs is drawing to a close for any application that aspires to be genuinely intelligent, reliable, and user-friendly. The limitations of first-generation memory solutions like RAG—characterized by context fragmentation and poor associative reasoning—highlight the necessity of a more structured, robust, and scalable approach.
The Model Context Protocol provides a compelling blueprint for this future. By standardizing the way context is provided to models, it enables a critical shift from building custom, one-off integrations to leveraging a reusable, interoperable ecosystem of specialized servers. This approach not only enhances model capabilities by grounding them in dynamic, factual knowledge but also addresses operational inefficiencies by optimizing token usage and reducing costs.
Based on this analysis, the following strategic recommendations are proposed for organizations considering the adoption of a memory-centric paradigm:
Prioritize Use Cases: Do not adopt MCP for trivial applications. Instead, focus on complex, high-stakes use cases where continuity of context, long-term memory, and factual consistency are paramount. Examples include personalized customer support agents, enterprise knowledge management systems, and autonomous agentic workflows.
Embrace a Phased Implementation: Begin with a minimal MCP server that exposes a single, high-value resource. Validate the architecture and its benefits before gradually adding more complex functionalities like tools and multi-server orchestration.
Invest in Foundational Infrastructure: Be aware that the cost of adoption is not just in the protocol but in the distributed systems infrastructure required to support it. A serverless platform like Google Cloud Run is an ideal starting point due to its ability to handle dynamic workloads and scale on demand, abstracting away the complexities of managing a distributed system.
In summary, the future of artificial intelligence is not solely about larger, more capable pre-trained models. It is about building intelligent systems that can reason over a persistent, external world of knowledge. Protocols like MCP are the blueprint for this next generation of intelligent systems, providing the critical foundation for transitioning from static predictors to dynamic, interactive, and truly valuable AI companions.
Enjoyed this post?
Share it with your network!